
Software Architecture Patterns in System Design: How a Small App Grows Without Falling Apart
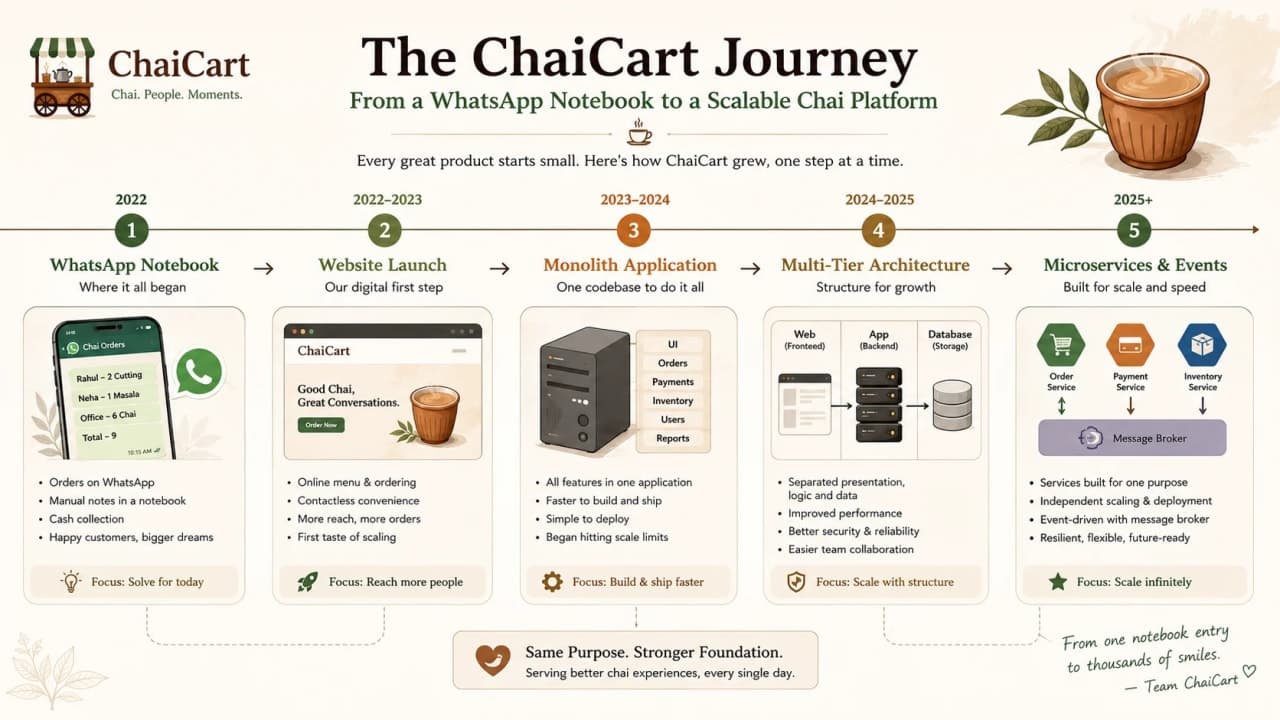
ChaiCart starts with one phone and one notebook. Then orders grow, layers appear, services split, and events help the system breathe.

ChaiCart's growth from notebook orders to a city-wide ordering platform.
ChaiCart did not begin as a distributed system. It began with one phone, one notebook, one payment QR code, and a founder who knew every regular customer by name. In the morning, orders came on WhatsApp. By evening, the same founder was checking inventory, confirming payments, packing snacks, and asking the delivery person why three addresses were still pending.
That tiny shop is the best way to understand architecture. Software architecture is the set of decisions that decides where responsibility lives before growth turns simple code into daily confusion. It is not a fancy diagram drawn after the real work. It is the shape of the work itself.
In this Dev Diaries article, we will grow ChaiCart step by step: monolith, layered architecture, 2-tier, 3-tier, N-tier, microservices, event-driven architecture, pub-sub, event streaming, CQRS, and event sourcing. We will not memorize patterns like glossary words. We will watch each pattern appear when the previous design starts feeling too heavy.
Reading promise: every pattern will arrive only after the business has a real problem. That is how architecture makes sense in interviews and in production.
1. ChaiCart Starts With One Phone and One Notebook
At the beginning, ChaiCart is not an app. It is a routine. Customers send messages. Someone writes down the item, address, and payment status. The cook prepares the order. The delivery person leaves with a few cups of tea and packets of snacks. If a customer calls, the founder remembers the order because there are only twenty orders a day.
This is important because architecture is not always required on day one. When the system is small, the process can be manual, direct, and personal. A notebook is not scalable, but it is understandable. It exposes the real workflow: receive order, validate menu, collect payment, prepare food, deliver, and handle complaints.
Then growth arrives. Office teams start ordering in bulk. A college hostel discovers the evening combo. People ask for coupons. Some want UPI confirmation. Some want cash on delivery. Suddenly the notebook is not a charming system. It is a bottleneck with handwriting.
Checkpoint: before choosing an architecture pattern, name the workflow in plain business language.
2. What Software Architecture Actually Means
Software architecture is the high-level structure of a software system. It describes the main components, how those components communicate, where data lives, how failure is handled, and how the system can change over time. The PDFs describe architecture as the arrangement of modules, layers, services, data stores, and interactions that influence scalability, maintainability, performance, and reliability.
In ChaiCart terms, architecture answers questions like: should checkout and admin live in the same application? Should payment confirmation happen inside the order request or later? Should the delivery team read from the same database as the order team? Should analytics slow down checkout? Should a coupon bug block the entire app?
A good architecture decision is not the most advanced pattern; it is the smallest structure that solves the current pressure without trapping the next stage of growth.
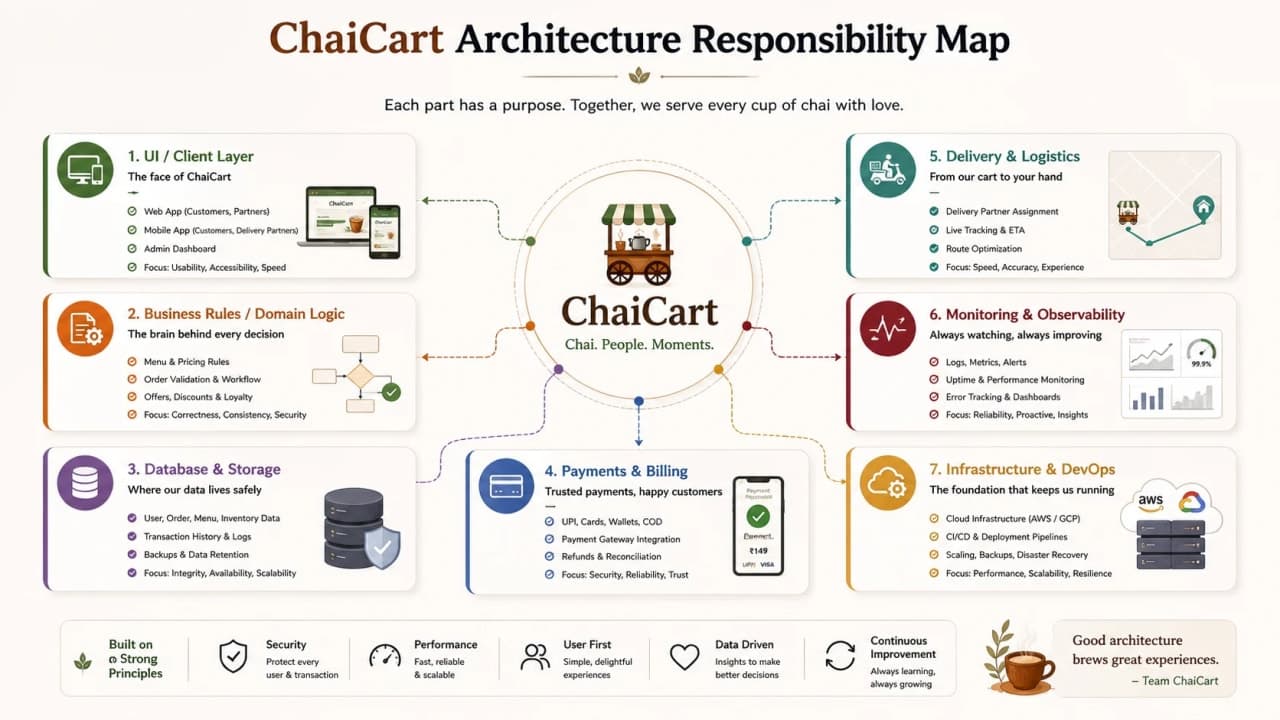
Architecture concern | Question it answers | ChaiCart example |
|---|---|---|
Responsibility | Who owns this behavior? | Order service owns order state |
Communication | How do parts talk? | API call, queue message, or event |
Data | Where is the truth? | Order database, payment ledger, event log |
Scalability | Which part grows independently? | Checkout scales more than admin |
Failure | What breaks when this breaks? | Coupon failure should not stop payment capture |
Change | How safely can we release? | Delivery ETA logic can change without touching menu |
Interview checkpoint: architecture is about responsibility, communication, data, change, scale, and failure. Patterns are names for common answers to those questions.
3. Why Architecture Matters in System Design Interviews
In a system design interview, architecture is where your answer stops sounding like a pile of components and starts sounding like a system. Many candidates list APIs, databases, caches, queues, load balancers, and CDNs. That is useful, but it is not enough. The interviewer wants to know why those parts exist, what problem each one solves, and what tradeoff you accepted.
For ChaiCart, a beginner answer might say, use microservices because they scale. A stronger answer says, start with a modular monolith because the team is small, then split payment and delivery when release ownership and independent scaling become real pressures. The second answer shows judgment.
Architecture is not a shopping list; it is the reasoning that connects business growth to technical boundaries.
Weak interview answer | Better interview answer |
|---|---|
Use microservices for everything. | Use a modular monolith until team ownership, scaling, and deployment pressure justify service boundaries. |
Add a queue because queues are scalable. | Use a queue when the user request should not wait for slow follow-up work. |
Use Kafka because it is powerful. | Use Kafka when durable event history, replay, and high-throughput streams are required. |
Use caching for performance. | Cache read-heavy, tolerance-friendly data such as menu and branch availability. |
Checkpoint: in interviews, say the trigger, the pattern, and the tradeoff in one breath.
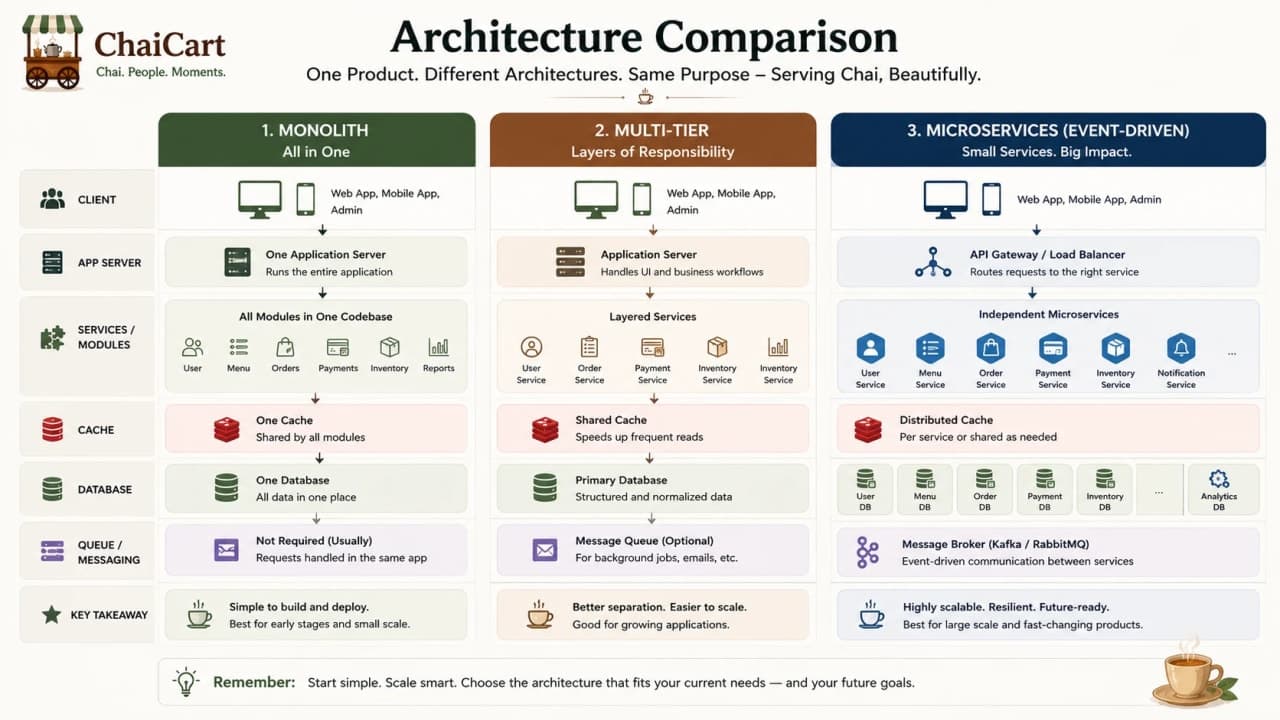
4. The First Real Application: A Monolith
ChaiCart's first app should be a monolith. One codebase has the customer site, admin panel, menu logic, cart, checkout, coupons, payment callbacks, delivery assignment, and basic reporting. It connects to one database. It is deployed as one application.
This sounds boring only if we confuse boring with bad. A monolith is often the right beginning because the team can move fast, understand the entire flow, debug locally, and ship one deployment. The founder does not need five services and three message brokers to sell tea to one neighborhood.
The important detail is that monolith does not mean messy. It means one deployable unit. Inside that unit, the code can still be organized into modules: order module, payment module, menu module, delivery module, and notification module.
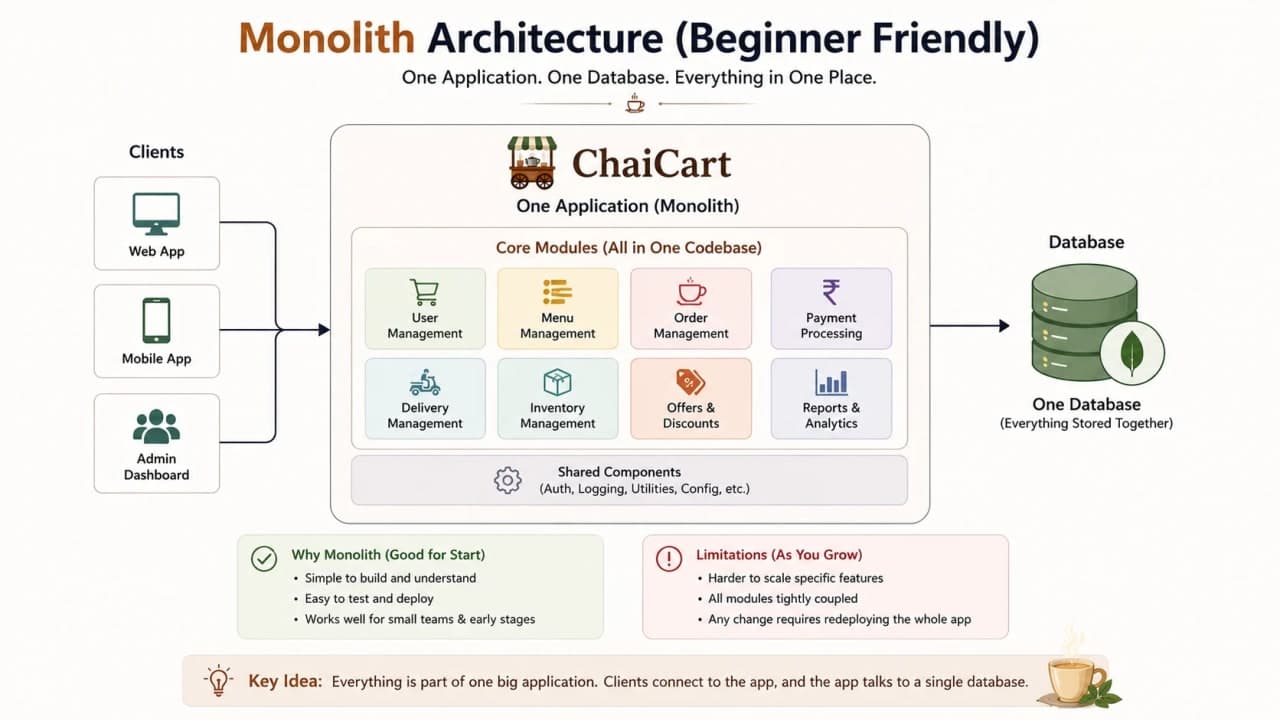
Monolith advantage | Why it helps ChaiCart early |
|---|---|
Simple development | One repository, one local setup, one mental model |
Simple deployment | One build and one release process |
Fast internal calls | Order code can call payment code inside the same process |
Easier transactions | One database transaction can update related tables |
Lower operational cost | No service mesh, broker fleet, or complex tracing yet |
Monolith disadvantage | When it starts hurting |
|---|---|
Tight coupling | Coupon changes accidentally affect checkout |
One scaling unit | Admin traffic and checkout traffic scale together |
Large deployments | Small changes require redeploying the whole app |
Shared failure blast radius | A memory leak in reporting can hurt ordering |
Team conflicts | Multiple teams edit the same code and database schema |
Checkpoint: a monolith is not a beginner mistake. A messy monolith is the mistake.
5. When the Monolith Becomes Heavy
The monolith begins to feel heavy during the evening rush. Checkout slows down, admin reports run expensive queries, payment callbacks arrive late, delivery assignment is manual, and support keeps refreshing the same screen. The first instinct may be to split everything into services. That is usually too early.
The better first question is: what exactly is heavy? Is the code hard to understand? Is the database overloaded? Are deployments risky? Are background jobs blocking user requests? Are teams stepping on each other? Each answer points to a different architectural move.
Do not split a monolith because it has grown; split or reshape it because a specific kind of growth is causing a specific kind of pain.
Pain | Likely first response | Pattern that may appear later |
|---|---|---|
Code is tangled | Layer modules clearly | Layered monolith |
Checkout traffic spikes | Scale app replicas and cache reads | N-tier or selected service split |
Payment callbacks are slow | Move retries to jobs | Event-driven workflow |
Reporting hurts checkout DB | Read replica or reporting projection | CQRS |
Teams release independently | Define ownership boundaries | Microservices |
Checkpoint: identify the type of heaviness before prescribing the pattern.
6. Layered Architecture: The First Cleanup
Layered architecture separates the application by responsibility. In a simple web app, the presentation layer handles UI and HTTP concerns, the business layer handles rules, the data access layer handles database work, and integration code handles external systems such as payment gateways and delivery providers.
For ChaiCart, the checkout route should not calculate coupon eligibility, update inventory, call the payment gateway, send notifications, and write raw SQL all in one file. That file becomes the shop counter, kitchen, accountant, and delivery desk at the same time. Layering gives each part a proper job.
Layered architecture often saves the monolith. It lets ChaiCart keep one deployable app while making the inside calmer. Tests become easier, changes become safer, and new developers can trace the flow without opening fifteen unrelated files.
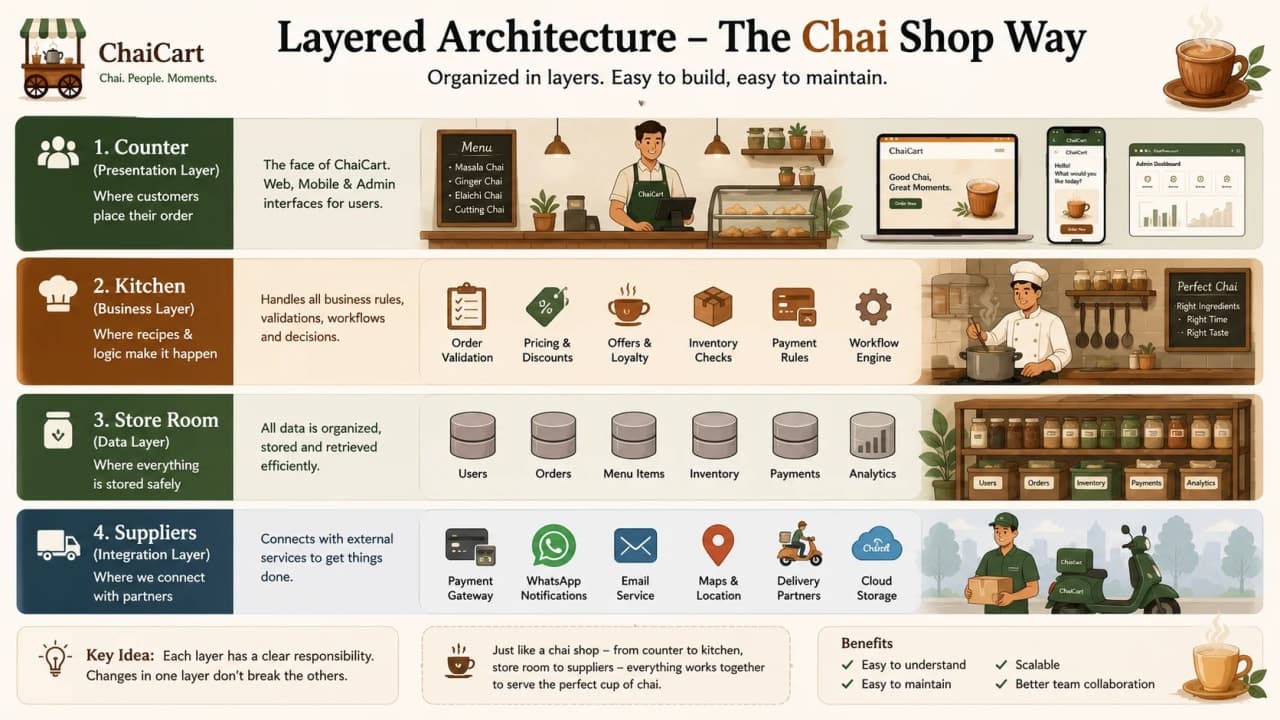
Layer | Responsibility | ChaiCart example |
|---|---|---|
Presentation | Accept input and return output | Checkout page and admin order table |
Controller or route | Translate request into application action | POST /orders |
Business service | Enforce rules | Validate menu availability and coupon limits |
Repository or data access | Read and write persistence | Create order row and update inventory |
Integration adapter | Talk to outside systems | Payment gateway and SMS provider |
Checkpoint: layered architecture is often the bridge between a quick monolith and a maintainable monolith.
7. Layered Architecture Tradeoffs
Layering gives ChaiCart cleaner responsibility boundaries, but it is not free. A tiny feature can require touching route, service, repository, DTO, validation, and test files. If the layers are created mechanically, the team may spend more time passing data through folders than solving user problems.
The best layered architecture is strict where correctness matters and flexible where the feature is simple. Payment capture deserves clear boundaries. A small static banner probably does not need a ceremony. The goal is not to worship layers. The goal is to keep important logic from leaking everywhere.
Layering benefit | Layering risk | Practical rule |
|---|---|---|
Clear separation of concerns | Too many pass-through files | Add layers where behavior has rules |
Better testing | Mocks everywhere | Prefer testing service behavior over internal plumbing |
Safer changes | False sense of safety | Keep database ownership and transactions explicit |
Easier onboarding | Folder maze | Name layers by responsibility, not fashion |
Checkpoint: layers should reduce confusion, not turn simple features into paperwork.
8. Client-Server: The Shape Everyone Already Knows
Before 2-tier and 3-tier, it helps to name the basic client-server idea. The client asks for something. The server responds. In ChaiCart, the customer app asks for the menu, sends an order, checks payment status, and receives delivery updates. The server owns the business rules and data.
Client-server architecture is not one specific deployment model. It is a communication shape. A browser talking to a server is client-server. A mobile app talking to an API is client-server. An admin dashboard talking to a backend is client-server. It becomes more specific when we decide how many tiers exist and what each tier owns.
Client responsibility | Server responsibility |
|---|---|
Render screens and collect user input | Validate requests and enforce business rules |
Show menu, cart, status, and errors | Calculate price, stock, payment, and delivery state |
Cache safe UI data locally | Protect source of truth and authorization |
Retry user-friendly requests | Handle idempotency and consistency |
Checkpoint: client-server tells you who asks and who answers; tiered architecture tells you where the answering work is divided.
9. 2-Tier Architecture: Client Talks to Database or Main Server
In 2-tier architecture, the client communicates directly with the data tier or a very thin server layer. Older desktop applications often used this style: the application had UI logic and business logic, then connected to a database. It can be simple and fast for small internal tools.
For ChaiCart, a 2-tier approach might be an internal admin desktop tool where branch staff update inventory directly against a central database. That could work for one trusted shop computer. It is usually a poor fit for public customer apps because it exposes too much responsibility to the client and makes security, scalability, and validation harder.
2-tier is acceptable for small trusted environments, but it is usually dangerous for public internet products where clients cannot be trusted.
2-tier aspect | Meaning | ChaiCart risk |
|---|---|---|
Client is heavy | UI may contain business logic | Coupon rules can be copied or bypassed |
Database is close | Fewer hops and simple setup | Credentials and access patterns become risky |
Scaling is limited | Many clients can stress the DB | Evening rush hits database directly |
Security is harder | Client has too much access | Inventory and order data exposure risk |
Checkpoint: 2-tier is simple, but public systems usually need a safer middle tier.
10. 3-Tier Architecture: The Classic Web App Shape
3-tier architecture separates the system into presentation tier, application tier, and data tier. The presentation tier is the browser or mobile app. The application tier handles APIs, business rules, authorization, and orchestration. The data tier stores the truth.
This is a natural fit for ChaiCart once customers order from a website or mobile app. The client never talks directly to the database. It talks to the ChaiCart API. The API validates the cart, checks inventory, calculates the bill, starts payment, writes the order, and returns a safe response.
2-tier | 3-tier |
|---|---|
Client may talk directly to database or a thin server | Client talks to application tier only |
Business logic can leak into client | Business logic belongs in application tier |
Good for small trusted internal tools | Good default for public web and mobile apps |
Security and scaling become hard | Middle tier improves security, validation, and scaling |
3-tier component | ChaiCart responsibility |
|---|---|
Presentation tier | Menu screen, cart, checkout, admin dashboard |
Application tier | Auth, pricing, coupon, order, payment, delivery rules |
Data tier | Orders, users, menu, inventory, payments, delivery assignments |
Checkpoint: 3-tier is the default mental model for most beginner-friendly web system design answers.
11. N-Tier Architecture: More Boundaries for More Pressure
N-tier architecture extends the 3-tier idea. Instead of only presentation, application, and data, the system may add a CDN, load balancer, API tier, service tier, cache tier, queue tier, worker tier, search tier, analytics tier, and storage tier. Each tier exists because a specific workload or risk needs its own boundary.
For ChaiCart, the evening menu can be cached. Images can live behind a CDN. Checkout APIs can sit behind a load balancer. Payment callbacks can go to a dedicated endpoint. Order-confirmation notifications can run in workers. Search can use a separate index. Reporting can use a read replica or analytics store.
The danger is that N-tier diagrams can become decorative. Adding tiers without a reason adds latency, cost, deployment work, monitoring work, and failure modes. Every tier should answer a sentence: we added this tier because...
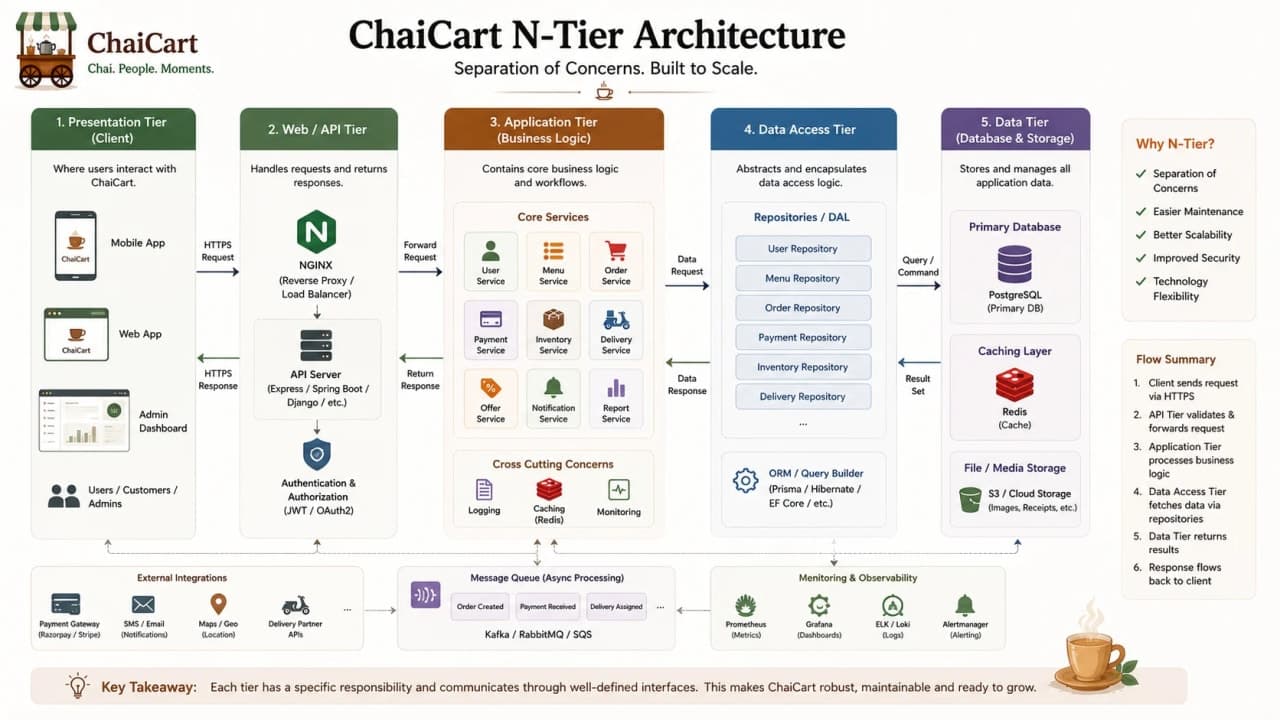
3-tier | N-tier |
|---|---|
Three broad tiers | Many specialized tiers |
Good for simple public apps | Good when workloads need separation |
Lower operational complexity | Higher operational complexity |
Fewer network hops | More hops but better isolation |
Tier added | Problem solved | Tradeoff |
|---|---|---|
CDN | Static assets and public pages load faster | Cache invalidation matters |
Load balancer | Distributes traffic across app instances | Health checks and routing rules matter |
Cache | Reduces repeated DB reads | Stale data risk |
Queue | Moves slow work out of request path | Eventual processing and retries matter |
Worker tier | Handles background jobs | Needs observability and retry safety |
Read replica | Protects primary DB from read-heavy screens | Replication lag risk |
Checkpoint: N-tier architecture is useful when each extra tier has a clear workload, risk, or ownership reason.
12. Choosing Between Monolith, Layered, 3-Tier, and N-Tier
At this point ChaiCart has four reasonable shapes. A simple monolith is best when the team is tiny and speed matters. A layered monolith is best when code clarity becomes the main problem. A 3-tier system is the normal public app shape. An N-tier system appears when specific workloads need their own infrastructure boundaries.
Notice what is not happening yet: we have not jumped to microservices. Many real companies get a long way with a well-structured monolith, 3-tier deployment, caches, queues, read replicas, and background workers. Microservices solve a different category of problem.
Factor | Prefer simpler monolith/layered | Consider N-tier or service split |
|---|---|---|
Team size | One small team owns most code | Multiple teams need independent ownership |
Traffic shape | All features scale similarly | Checkout, search, and notifications scale differently |
Release risk | One deployment is manageable | Small changes need independent release cycles |
Data consistency | Strong transactions matter everywhere | Boundaries can tolerate eventual consistency |
Operational maturity | Limited DevOps and monitoring | Strong CI/CD, tracing, alerts, and on-call exist |
Checkpoint: simpler architecture is not less professional when it fits the stage.
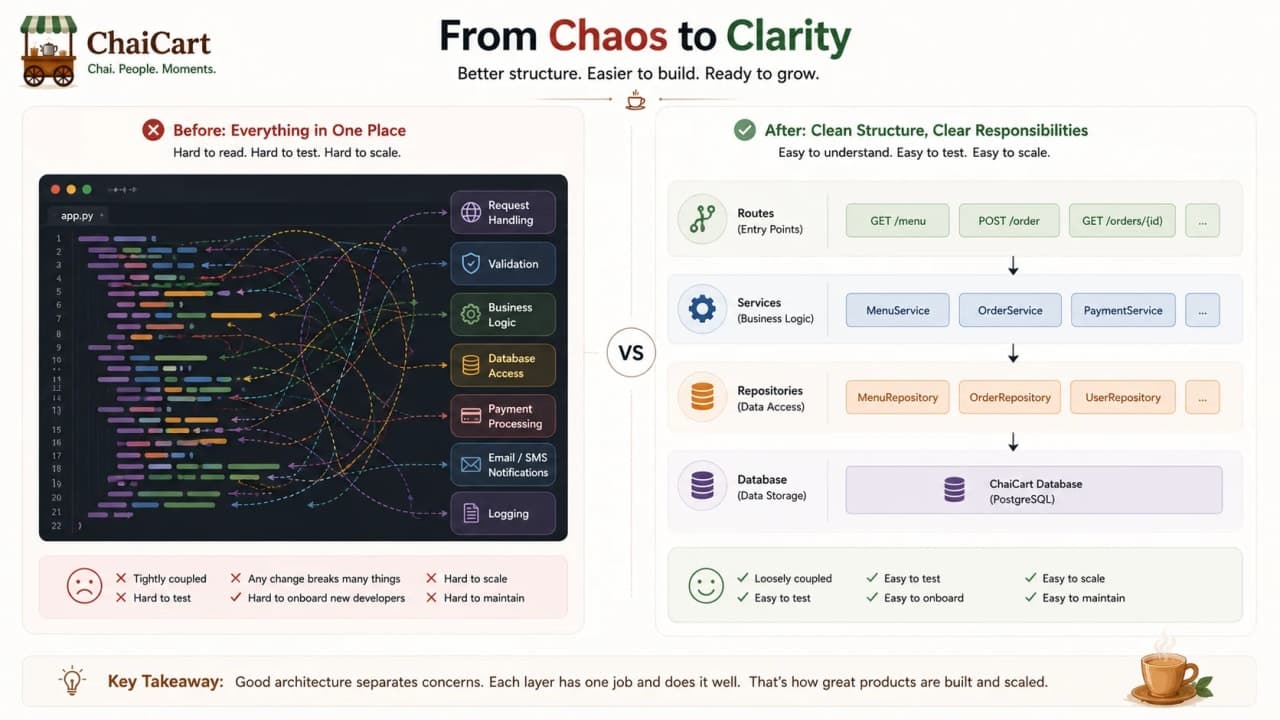
13. Modular Monolith: The Architecture Many Teams Actually Need
A modular monolith is still one deployable app, but its internal modules have clear boundaries. Order code does not casually reach into payment tables. Coupon logic has a public interface. Delivery assignment is not scattered across checkout, admin, and support files. This pattern keeps local development and deployment simple while teaching the codebase to respect ownership.
For ChaiCart, a modular monolith might have modules named Menu, Cart, Order, Payment, Delivery, Coupon, Notification, User, and Reporting. The modules communicate through functions or internal interfaces, not random imports across the entire codebase.
A modular monolith is often the safest training ground for future microservices because it proves the boundaries before adding network calls.
modules/
order/
order.service
order.repository
order.events
payment/
payment.service
payment.gateway
delivery/
delivery.service
delivery.repository
Rule: checkout may call order.service, but it should not write payment tables directly.Line by line, the sketch says that order, payment, and delivery are separate modules inside one codebase. Each module owns service code and persistence code. The final rule is the important part: modules should collaborate through intentional interfaces, not by editing each other's private data.
Checkpoint: if a boundary is not clear inside a monolith, it will not magically become clear after becoming a service.
14. Microservices: When Independent Ownership Becomes Real
Microservices architecture splits the system into small, independently deployable services organized around business capabilities. Martin Fowler's microservices guide describes services as independently deployable and organized around business capability, often communicating through lightweight mechanisms. For ChaiCart, that might mean separate services for Order, Payment, Delivery, Menu, Coupon, Notification, User, and Support.
The key word is not small. The key word is independent. The payment team can release payment retry logic without redeploying menu pages. The delivery team can scale ETA workers without scaling admin dashboards. The notification team can change SMS providers without touching checkout rules.
But independence has a price. Each service needs deployment, monitoring, logging, security, data ownership, versioning, and failure handling. Network calls can fail. Data is not automatically consistent. Debugging one user order may require tracing five systems.
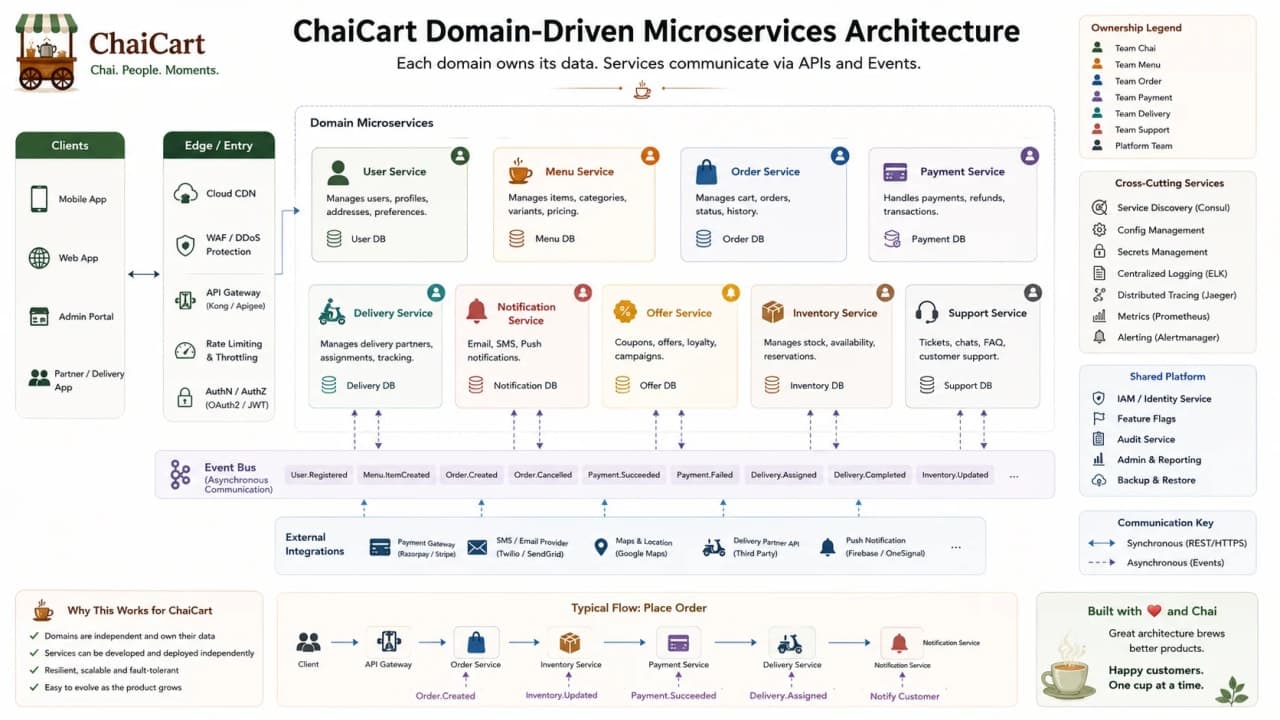
Microservice | Owns | Should not own |
|---|---|---|
Order service | Order lifecycle and state transitions | Payment provider secrets |
Payment service | Payment attempts, captures, refunds, ledger | Menu availability |
Delivery service | Assignment, ETA, delivery state | Coupon rules |
Menu service | Items, prices, availability | Customer identity |
Notification service | Email, SMS, push delivery | Order source of truth |
Coupon service | Campaign rules and redemptions | Payment settlement |
Checkpoint: microservices are about independent business ownership, not simply breaking files into smaller pieces.
15. Monolith vs Microservices
The monolith-versus-microservices debate becomes clearer when ChaiCart is the example. If one team is building the first product, a monolith gives speed. If five teams own five business capabilities and release every week, microservices can reduce coordination. If the system needs strict transactions across many features, a monolith is easier. If only delivery tracking needs massive independent scale, a service split may be justified.
The wrong answer is to treat microservices as the graduation certificate of architecture. Many systems fail because they copied the final architecture of a large company without copying the team size, deployment maturity, observability, and business pressure that made that architecture necessary.
Dimension | Monolith | Microservices |
|---|---|---|
Deployment | One app deployed together | Services deployed independently |
Data | Often one shared database | Prefer database ownership per service |
Scaling | Scale whole app or selected tiers | Scale specific services |
Transactions | Simpler local transactions | Distributed consistency patterns required |
Debugging | Local call stack is easier | Requires logs, traces, correlation IDs |
Team fit | Small team or early product | Multiple teams and mature operations |
Failure | One bug can affect whole app | Failures can be isolated but network risk increases |
Checkpoint: choose microservices when independence is worth operational complexity.
16. Microservice Granularity: How Small Is Too Small?
A common beginner mistake is to make every noun a service. ChaiCart does not need TeaService, SnackService, CupService, SugarLevelService, and AddressLineTwoService. Services should represent meaningful business capabilities with their own data, rules, and reason to change independently.
Granularity is a judgment call. The Order service is a good boundary because order state is central and changes often. Payment is a good boundary because it has provider integrations, retries, reconciliation, and security concerns. A tiny DiscountLabel service probably creates more network traffic than value.
Boundary signal | Good service candidate? | Why |
|---|---|---|
Owns important data | Yes | Payment ledger should have strong ownership |
Needs independent scaling | Yes | Notifications can spike after bulk campaigns |
Changes for different business reasons | Yes | Delivery rules change differently from menu rules |
Only wraps one function | Usually no | Function calls do not need network hops |
Exists because diagram looks balanced | No | Architecture is not interior decoration |
Checkpoint: a service should be big enough to own a business capability and small enough to change without dragging the whole system.
17. Data Ownership in Microservices
The hardest part of microservices is rarely the API. It is data. If every service reads and writes the same shared database, the services are independent in name only. A payment schema change can break orders. A delivery report can query private order tables. Soon the database becomes the real monolith.
Database-per-service means each service owns its data and exposes behavior through APIs or events. The Order service owns orders. The Payment service owns payments. The Delivery service owns delivery assignments. Other services cannot casually write those tables.
In microservices, data ownership is the boundary; the API is only the doorway.
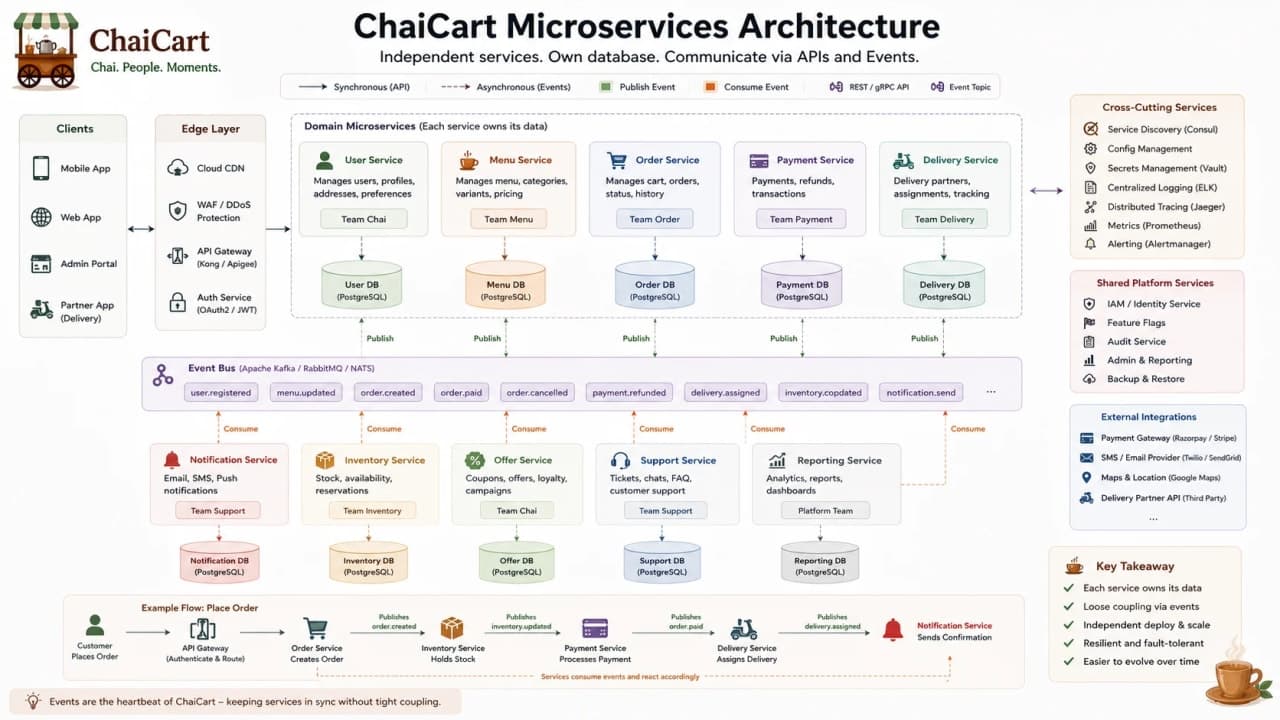
Approach | Benefit | Risk |
|---|---|---|
Shared database | Simple reporting and joins | Tight coupling and hidden dependencies |
Database per service | Clear ownership and independent evolution | Harder cross-service queries and consistency |
Read model/projection | Fast queries across domains | Event lag and rebuild complexity |
API composition | No direct data sharing | Higher latency and partial failure handling |
Checkpoint: if service A can freely update service B's tables, the architecture boundary is mostly decorative.
18. The Consistency Problem
In the monolith, ChaiCart can place an order and update inventory in one local database transaction. In microservices, the Order service, Payment service, Inventory or Menu service, and Delivery service may own different databases. A single transaction across all of them becomes slow, fragile, or unavailable.
This is where eventual consistency appears. ChaiCart may create an order as PENDING_PAYMENT, send a payment request, receive a payment captured event, then mark the order PAID. For a short period, different parts of the system may not agree. That is acceptable only if the product is designed for it.
Users should see clear status: payment processing, order confirmed, delivery assigned, refund pending. Support tools should explain what happened. Retry systems should avoid double charging. Consistency is not just a database property; it is a user experience property.
Consistency pattern | Use case | ChaiCart example |
|---|---|---|
Local transaction | Single service owns all data involved | Create order row and order items |
Saga | Multi-step workflow across services | Order -> payment -> delivery -> notification |
Outbox pattern | Publish events reliably after DB write | Order service stores OrderPlaced event with order transaction |
Idempotency key | Avoid duplicate side effects | Payment callback processed once |
Read projection | Fast cross-domain reads | Support dashboard combines order, payment, delivery status |
Checkpoint: if you choose microservices, explain how consistency will work without pretending distributed transactions are free.
19. Synchronous Communication
Synchronous communication means one service calls another and waits for the response. During checkout, the Order service might call Payment service and wait for payment authorization. This is easy to reason about because the caller gets an answer now.
Synchronous calls are useful when the user cannot continue without the answer. If ChaiCart must know whether payment is authorized before confirming the order, waiting makes sense. But if analytics, loyalty points, support notifications, or marketing emails run inside the same request, the customer waits for work that does not need to happen immediately.
Synchronous calls are best for decisions the user is actively waiting on; asynchronous work is better for follow-up tasks.
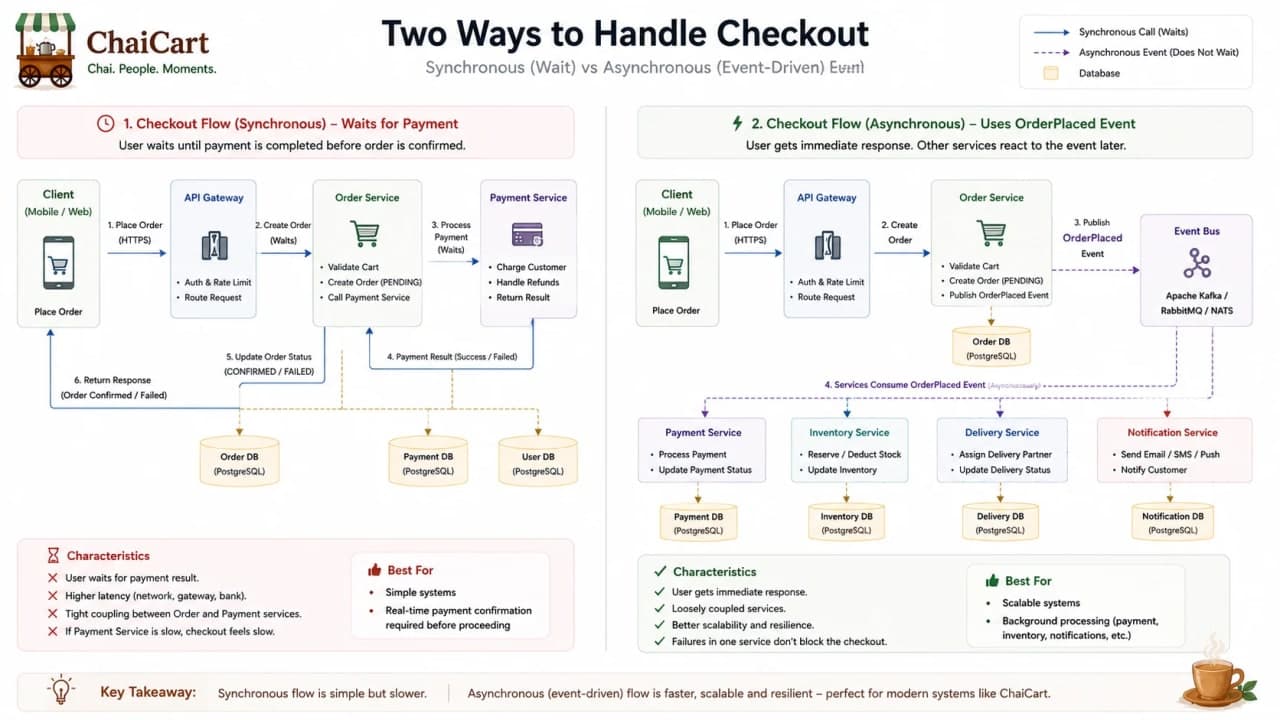
Communication style | Use when | Avoid when |
|---|---|---|
Synchronous API call | Caller needs an immediate answer | The callee is slow, unreliable, or not user-critical |
Asynchronous queue | Work can happen after the request | User needs a confirmed result immediately |
Event stream | Multiple consumers need durable event history | Simple one-off task is enough |
Checkpoint: ask whether the user is waiting. If not, the work may belong outside the request path.
20. Asynchronous Communication and Queues
Asynchronous communication lets the system accept work now and process it later. ChaiCart can create an order, return a response, and let background workers send SMS, update analytics, assign delivery, or notify loyalty systems. The user gets a faster checkout, and slow follow-up work no longer blocks the request.
Queues also absorb bursts. During the evening rush, 5,000 order confirmation messages may arrive in a few minutes. Workers can process the queue steadily. If the SMS provider is slow, messages wait instead of crashing checkout.
The tradeoff is delayed completion. A queued notification might arrive a few seconds late. A failed job needs retry rules. A duplicate message must not create duplicate loyalty points. Asynchrony is powerful, but it shifts the system from immediate certainty to managed progress.
event: OrderPlaced
payload:
orderId: ORD-9042
customerId: CUST-77
branchId: BRANCH-KORAMANGALA
totalAmount: 420
occurredAt: 2026-07-02T18:40:00+05:30The first line names the event as something that already happened. The payload carries the minimum useful facts: order ID, customer ID, branch, amount, and timestamp. Consumers should not need to ask the Order service for every tiny detail just to do basic work.
Checkpoint: asynchronous design needs event names, retry rules, idempotency, and user-visible status.
21. Event-Driven Architecture
Event-driven architecture is a style where services publish facts about things that happened, and other services react to those facts. AWS describes event-driven systems through producers, brokers, and consumers. The producer emits an event, the broker routes or stores it, and consumers process it without the producer needing to know every downstream action.
For ChaiCart, Order service publishes OrderPlaced. Payment service may react by starting payment capture. Notification service may send a message. Analytics may update dashboards. Loyalty may calculate points. The Order service does not call all of them one by one inside checkout.
Event-driven architecture reduces direct coupling by letting services react to business facts instead of being commanded by one central request.
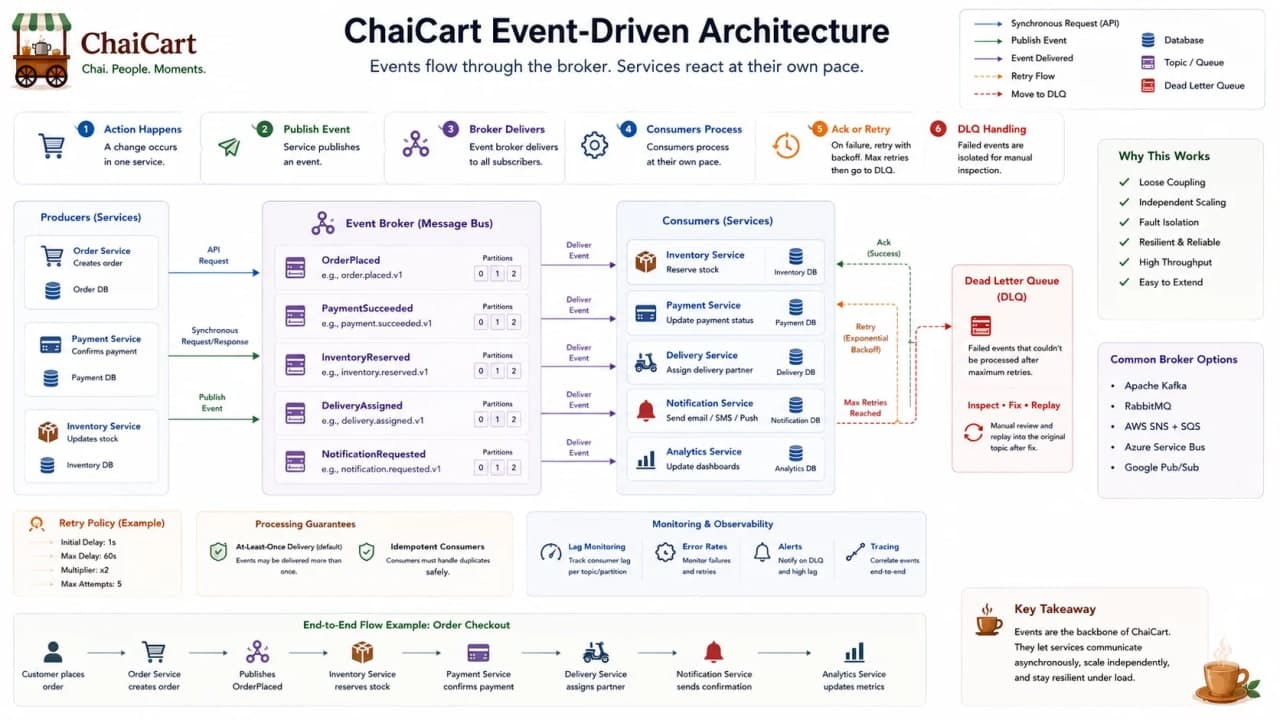
EDA component | Responsibility | ChaiCart example |
|---|---|---|
Producer | Publishes event | Order service emits OrderPlaced |
Broker | Routes or stores event | Queue, event bus, or stream |
Consumer | Processes event | Notification service sends SMS |
Event schema | Defines event shape | orderId, customerId, occurredAt |
Dead-letter queue | Stores repeatedly failing messages | Bad notification payload for investigation |
Checkpoint: in EDA, name events as past-tense facts: OrderPlaced, PaymentCaptured, DeliveryAssigned.
22. Event-Driven Tradeoffs
Event-driven systems are excellent for decoupling, bursts, and multi-consumer workflows. They also introduce subtle problems: duplicate messages, out-of-order delivery, delayed consistency, schema changes, poison messages, replay safety, and difficult debugging. A beginner architecture answer should not hide these tradeoffs.
If ChaiCart publishes OrderPlaced twice, notification should not send two confirmations. If PaymentCaptured arrives before the support projection has seen OrderPlaced, the projection should recover. If a consumer cannot parse an event after a deploy, the system needs a dead-letter path and alerting.
Event-driven challenge | What can go wrong | Practical response |
|---|---|---|
Duplicate events | Double SMS or double loyalty points | Idempotency keys and processed-event table |
Out-of-order events | DeliveryAssigned appears before PaymentCaptured | Partition/order by aggregate ID where needed |
Eventual consistency | Screens disagree briefly | Show honest status and build projections carefully |
Poison messages | One bad message retries forever | Retry limit and dead-letter queue |
Schema evolution | Old consumers break on new payload | Version events and keep backward compatibility |
if processedEvents.exists(event.id):
return "already handled"
try:
sendOrderConfirmation(event.orderId)
processedEvents.insert(event.id)
except TemporaryProviderError:
retryWithBackoff(event)
except PermanentPayloadError:
moveToDeadLetterQueue(event)The first check prevents duplicate side effects. The try block performs the business action. Temporary provider errors are retried with backoff. Permanent payload errors move to a dead-letter queue so one bad event does not block the whole consumer.
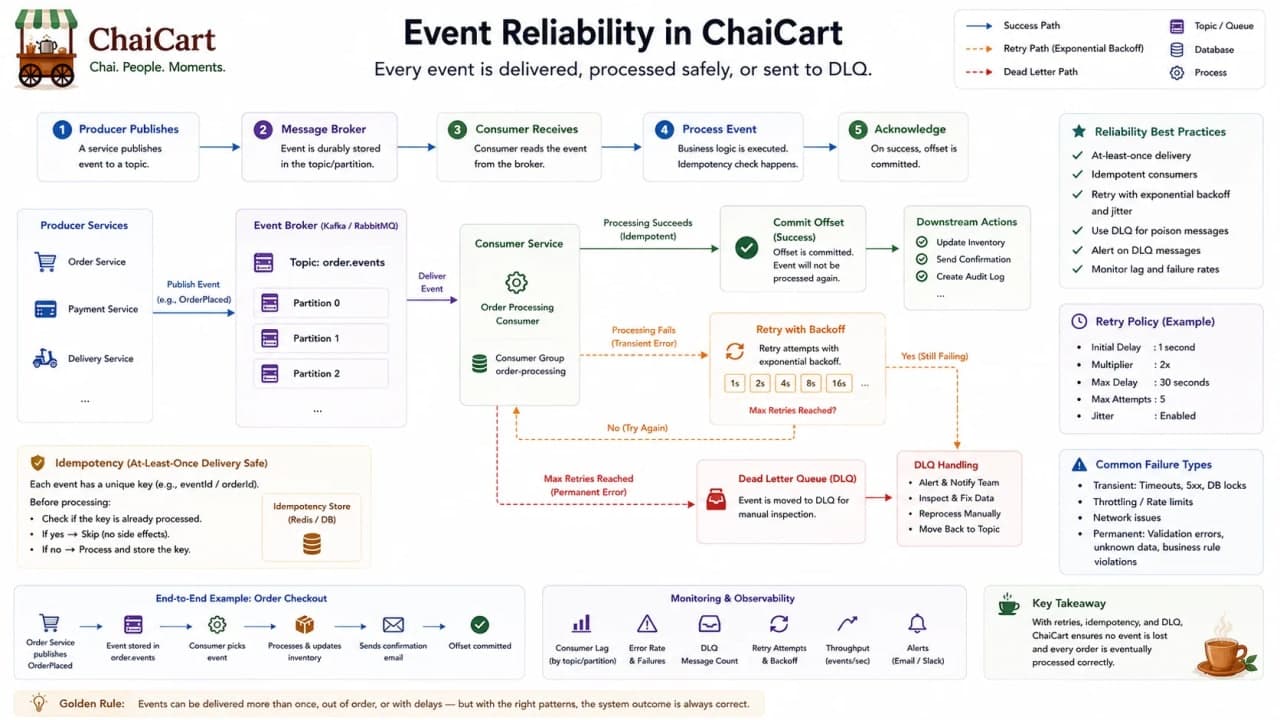
Checkpoint: event-driven architecture is not fire-and-forget. It is fire, track, retry, and investigate.
23. Pub-Sub vs Event Streaming
Publish-subscribe and event streaming are related, but they are not the same mental model. In pub-sub, a producer publishes a message and active subscribers receive it through exchanges, topics, or event buses. In event streaming, events are stored in a durable log so consumers can read at their own pace, replay history, and process streams over time.
RabbitMQ's publish-subscribe tutorial shows the idea of broadcasting messages to multiple receivers through an exchange. Kafka's introduction describes event streaming as capturing real-time data as streams of events, storing those streams durably, and processing them in real time or retrospectively. That difference matters when ChaiCart needs audit history or replay.
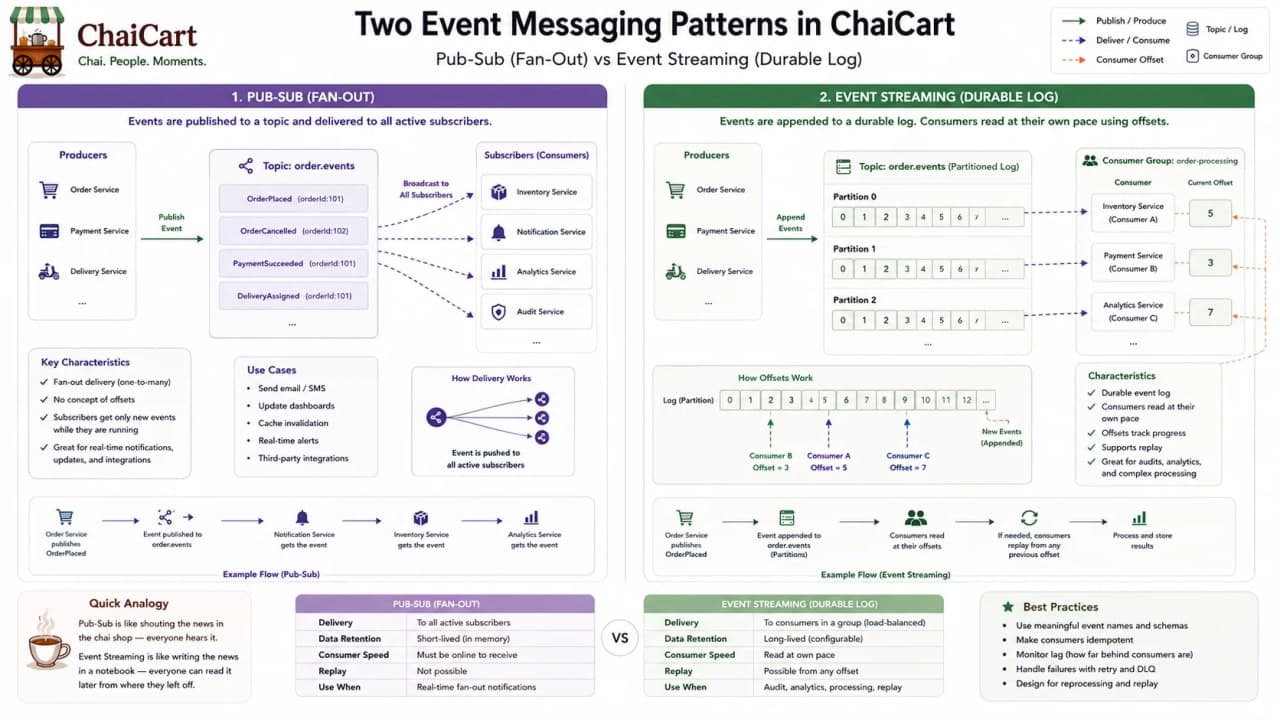
Dimension | Pub-Sub | Event Streaming |
|---|---|---|
Main idea | Broadcast message to subscribers | Append events to durable log |
History | Often transient or queue-retained | Durable retention and replay |
Consumer pace | Active subscribers receive messages | Consumers track offsets |
Great for | Notifications, fanout, simple decoupling | Audit, analytics, replay, high-throughput pipelines |
ChaiCart use | Send order notifications to active consumers | Replay all orders to rebuild analytics projection |
Tool | Typical fit | ChaiCart example |
|---|---|---|
Kafka | Durable event streaming, replay, high throughput | Order event log and analytics stream |
RabbitMQ | Messaging, queues, routing, pub-sub style fanout | Background notification jobs |
AWS EventBridge | Managed event bus and SaaS/AWS integration | Route business events between cloud services |
Checkpoint: choose pub-sub for simple fanout; choose event streaming when history, replay, ordering, and stream processing matter.
24. CQRS: Separate Write Model and Read Model
CQRS stands for Command Query Responsibility Segregation. The simple idea is that the model used to write data does not have to be the same as the model used to read data. Microsoft describes CQRS as separating read and write operations, which can help when read and write workloads have different shapes.
For ChaiCart, checkout writes are strict: create order, validate price, reserve stock, start payment. Support reads are broad: show order, payment, delivery, customer messages, refund status, and timeline in one screen. Forcing both workloads into one database model can make either writes slow or reads painful.
With CQRS, the write side protects order correctness. Events or jobs build a read model optimized for support dashboards, branch dashboards, or customer tracking. The tradeoff is eventual consistency: the read model can lag behind the write model.
CQRS side | Optimized for | ChaiCart example |
|---|---|---|
Command/write model | Correct state changes | PlaceOrder, CapturePayment, AssignDelivery |
Query/read model | Fast user screens | Order timeline dashboard |
Projection worker | Build read views | Consumes OrderPlaced and PaymentCaptured |
Lag handling | Honest status | Show processing state until projection updates |
Checkpoint: CQRS is useful when reads and writes are pulling the model in different directions.
25. Event Sourcing: Store Facts, Rebuild State
Event sourcing stores state changes as a sequence of events instead of storing only the latest state. Microsoft's event sourcing pattern describes using an append-only store where events are the source of truth. The current state can be rebuilt by replaying events.
For ChaiCart, an order might have events: OrderPlaced, PaymentCaptured, KitchenAccepted, DeliveryAssigned, Delivered, RefundRequested. Instead of only seeing status = DELIVERED, support can inspect the timeline of how the order reached that state. This is powerful for audit, debugging, and replay.
It is also advanced. Event design becomes serious. Schema versioning matters. Rebuilding projections can be expensive. Developers must think in events, not simple row updates. Event sourcing is a sharp tool; it should not be the default for a basic CRUD app.
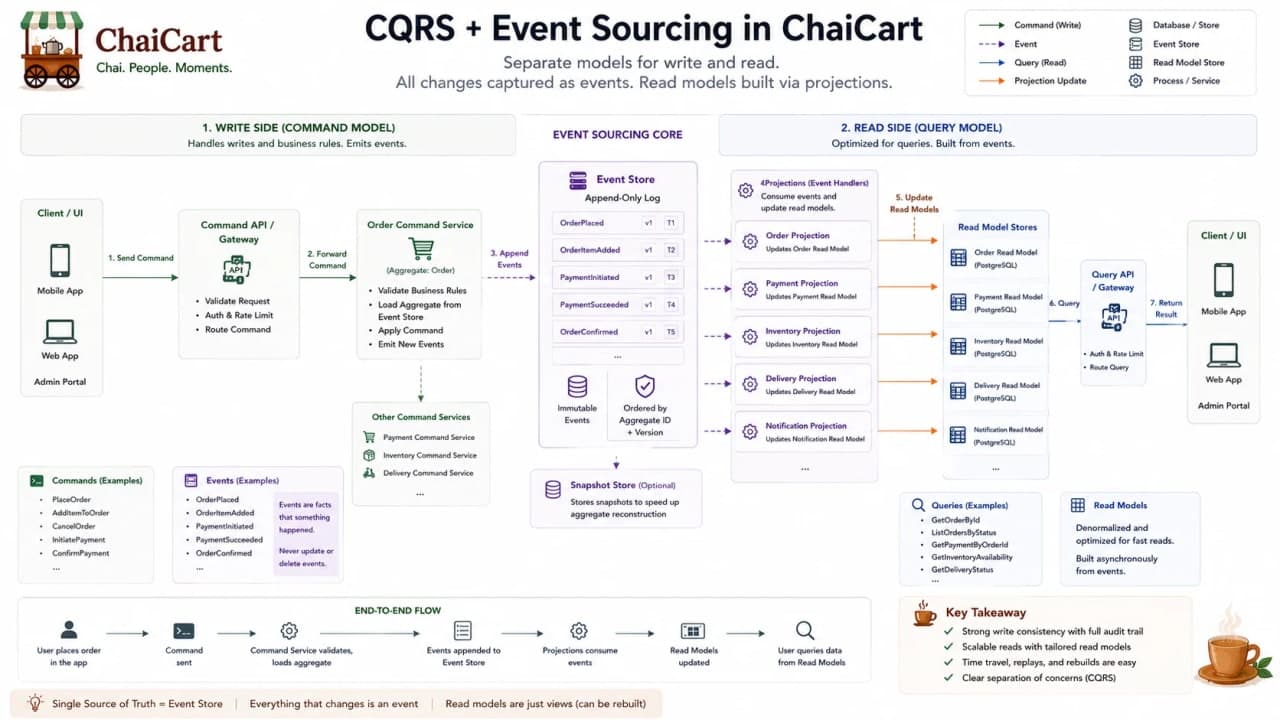
OrderPlaced(orderId=9042, amount=420)
PaymentCaptured(orderId=9042, paymentId=PAY-11)
KitchenAccepted(orderId=9042, branchId=KORAMANGALA)
DeliveryAssigned(orderId=9042, riderId=RIDER-8)
OrderDelivered(orderId=9042, deliveredAt=18:58)Each line is a fact in time. The current order status can be rebuilt by replaying the stream. The audit trail is not an afterthought; it is the data model.
Checkpoint: event sourcing is valuable when history is as important as current state.
26. Architecture Evolution Map
ChaiCart should not jump from notebook to event-sourced microservices. The healthier path is evolutionary. Start manual. Build a monolith. Organize it as a layered modular monolith. Add 3-tier deployment. Add N-tier infrastructure where traffic demands it. Split selected services only when ownership, scaling, or release pressure is real. Add event-driven flows for background work and fanout. Use CQRS or event sourcing only for the specific areas that justify the complexity.
This is the architecture staircase. Each step exists because the previous step is now too small for a clearly named pressure.
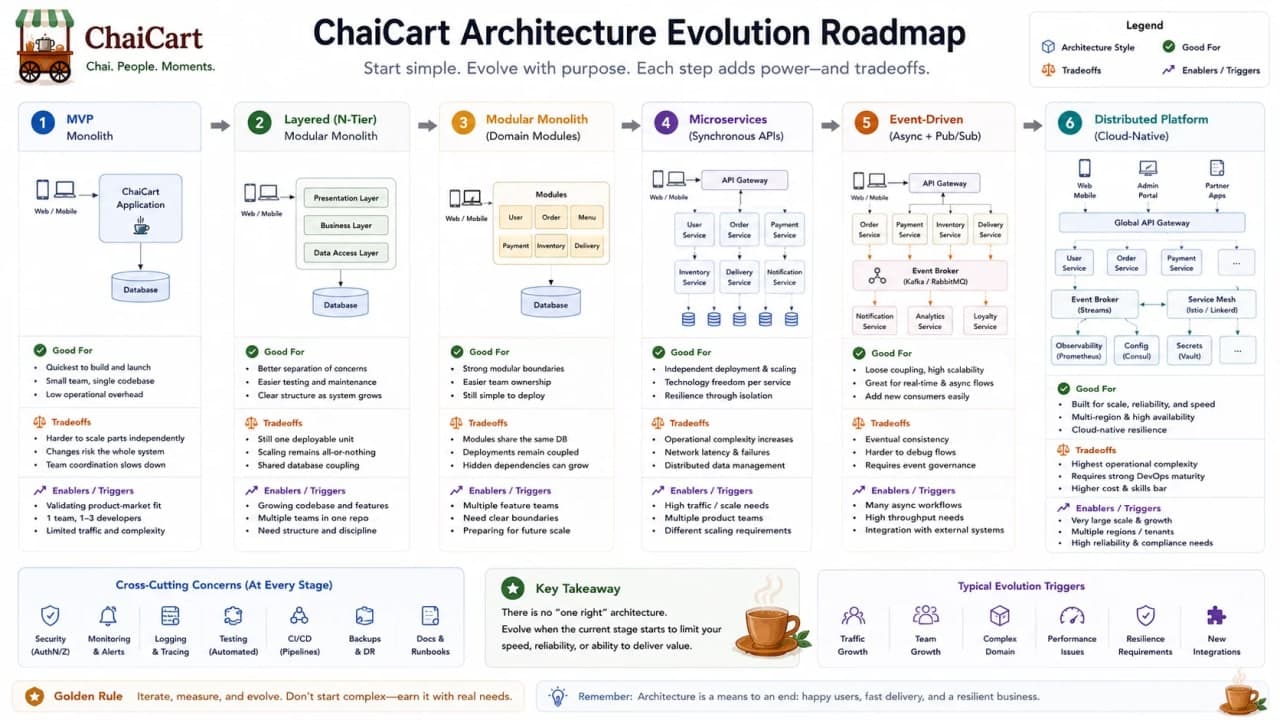
Stage | Architecture shape | Why it appears |
|---|---|---|
Notebook and phone | Manual process | Validate business workflow |
First web app | Monolith | Move fast with one team |
Growing codebase | Layered modular monolith | Keep responsibilities clear |
Public traffic | 3-tier/N-tier | Improve security, scaling, and infrastructure boundaries |
Multiple teams | Selected microservices | Independent ownership and deployment |
Many side effects | Event-driven workflows | Decouple slow follow-up work |
Read/write pressure | CQRS or event sourcing | Specialized models and audit history |
Checkpoint: architecture should evolve from pressure, not from ambition.
27. Decision Framework for Interviews
When an interviewer asks you to design an ordering platform like ChaiCart, do not begin with the final diagram. Begin with constraints. How many users? What is the peak traffic? How many teams? Does checkout require strong consistency? Can notifications be delayed? What happens if payment is slow? What data must be audited? How quickly must different parts be released?
Then pick the smallest architecture that fits those answers. A simple ordering MVP can be a modular monolith with 3-tier deployment. A city-wide platform may add cache, queue, workers, read replicas, and selected services. A national platform with multiple teams may use microservices and event-driven architecture more heavily.
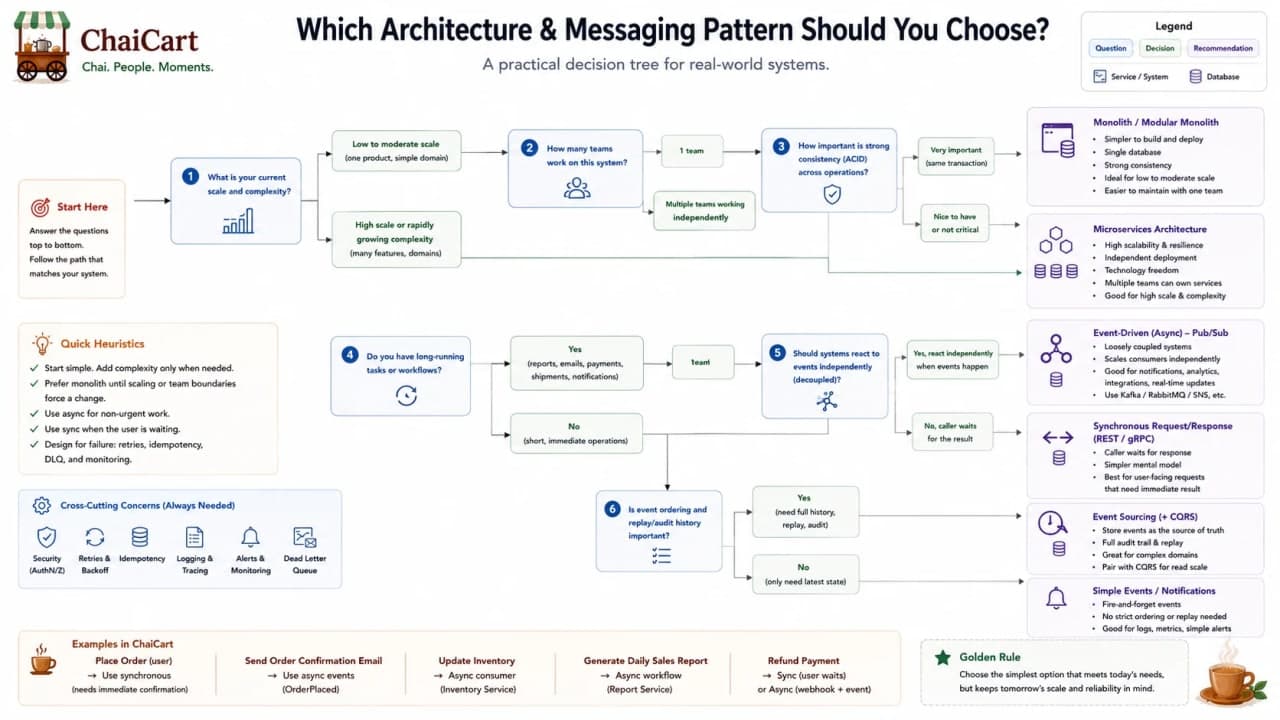
Question | If answer is yes | Likely pattern |
|---|---|---|
Is one small team building the product? | Yes | Monolith or modular monolith |
Is public client security important? | Yes | 3-tier architecture |
Do workloads scale differently? | Yes | N-tier and selected scaling boundaries |
Do teams need independent release cycles? | Yes | Microservices for real business capabilities |
Can follow-up work happen later? | Yes | Queues or event-driven workflows |
Do you need replayable history? | Yes | Event streaming or event sourcing |
Are reads and writes very different? | Yes | CQRS/read projections |
Interview one-liner: start simple, modularize early, split only where pressure proves the boundary.
28. Common Architecture Mistakes
Architecture mistakes usually come from choosing a pattern before understanding the pressure. ChaiCart can over-engineer itself into a maze, under-engineer itself into chaos, or mix patterns without owning the tradeoffs.
The most common mistake is premature microservices. The second is a monolith with no internal boundaries. The third is event-driven architecture with no idempotency, dead-letter queue, or schema versioning. The fourth is N-tier infrastructure that adds latency without reducing risk.
Mistake | Why it hurts | Better move |
|---|---|---|
Microservices on day one | Operational complexity arrives before business need | Start with modular monolith |
No module boundaries | Every change touches everything | Layer and define ownership |
Shared DB across services | Services become tightly coupled | Use data ownership or intentional read models |
Queue without retries | Failures disappear or loop forever | Add retry policy, idempotency, and DLQ |
Kafka for tiny tasks | Heavy tool for simple job | Use a simple queue or managed event bus |
Ignoring user status | Eventual consistency confuses users | Expose processing, confirmed, failed, and retry states |
Checkpoint: every advanced pattern has an invoice. Make sure the business problem can pay it.
29. Interview Mental Models
A mental model is more useful than a memorized definition. Think of monolith as one building. Layered architecture is floors inside that building. 3-tier is customer area, kitchen, and storage separated. N-tier adds specialized counters, cold storage, dispatch desk, and reporting room. Microservices are separate shops with contracts. Event-driven architecture is a notice board where each team reacts to posted facts.
These metaphors are not perfect, but they help you explain tradeoffs under pressure. The interviewer does not need you to sound like a textbook. They need to see that you can reason from requirement to pattern to risk.
Pattern | Mental model | Interview sentence |
|---|---|---|
Monolith | One building | Good when one team needs speed and shared transactions |
Layered | Floors inside one building | Good when responsibilities need clarity |
3-tier | Counter, kitchen, storage | Good default for public apps |
N-tier | Specialized rooms | Good when workloads need separate scaling or isolation |
Microservices | Separate shops with contracts | Good when independent ownership matters |
Event-driven | Notice board of facts | Good when many consumers react to the same business event |
CQRS | Separate ordering desk and status screen | Good when writes and reads need different models |
A Sample ChaiCart Interview Walkthrough
Here is how I would narrate the architecture in an interview. I would begin with the simplest realistic version: ChaiCart is a chai and snacks ordering platform where customers browse a menu, place an order, pay online or choose cash, track delivery, and contact support. Branch staff manage availability. Admins see order volume, menu performance, payment failures, and delivery delays. That description already contains the main domains: menu, cart, order, payment, delivery, notification, support, and reporting.
For the MVP, I would choose a modular monolith with 3-tier deployment. The browser and mobile app are the presentation tier. A backend application exposes APIs and contains modules for order, payment, delivery, menu, coupon, and notification. A relational database stores users, menu items, inventory, orders, payments, and delivery assignments. This is intentionally simple because one small team can understand the whole system, deploy quickly, and keep transactions easy.
Then I would protect the design from becoming a messy monolith. I would keep route handlers thin. The Order module would expose order actions. The Payment module would hide provider details. The Delivery module would own assignment and ETA rules. The Menu module would own availability and price rules. Repositories would handle persistence. This keeps the code ready for growth without paying microservice costs too early.
Next I would discuss the first scaling moves. Menu and product images are read-heavy, so I would use CDN and cache for public menu data that can tolerate short staleness. Checkout stays on the API tier because it needs validation and write consistency. Notifications move to a queue because the customer should not wait for SMS, email, push, analytics, and loyalty updates. Reporting should avoid hammering the primary order database, so I would introduce read replicas or projections when dashboards become expensive.
If the interviewer increases traffic, I would scale the web and API tiers horizontally behind a load balancer. I would add database indexes around order lookup, branch availability, and payment status. I would add idempotency keys to checkout and payment callbacks so retries do not create duplicate orders or double captures. I would track correlation IDs from checkout through payment, notification, delivery, and support screens so debugging does not become a guessing game.
If the interviewer increases team size, I would not split everything at once. I would identify the first real service candidates. Payment is a strong candidate because it has provider integration, retries, reconciliation, security concerns, and independent release risk. Notification is another candidate because it can scale independently and can fail without blocking checkout. Delivery may become separate if routing, rider assignment, and ETA logic grow into their own business capability.
For microservices, I would give each service clear data ownership. Order service owns order state. Payment service owns payment attempts, captures, refunds, and ledger records. Delivery service owns assignment and delivery status. Notification service owns delivery attempts for SMS, email, and push. Cross-service screens should use APIs or read projections, not direct table access. This is the difference between real service boundaries and a shared database with extra network calls.
For event-driven flows, I would publish events for facts: OrderPlaced, PaymentCaptured, PaymentFailed, DeliveryAssigned, OrderDelivered, RefundRequested. Payment and delivery might still need synchronous calls in some user-critical paths, but analytics, notifications, loyalty, and support timeline updates can consume events asynchronously. I would add retries, dead-letter queues, idempotent consumers, event schema versioning, and monitoring from the start because event systems without reliability rules become very hard to trust.
Finally, I would explain what I would not build yet. I would not use event sourcing for the entire product unless audit history and replay are first-class requirements. I would not introduce Kafka if a simple queue or managed event bus solves the first background-work problem. I would not create a service per table. I would not make the API Gateway a hidden monolith full of business rules. The strongest architecture answer often includes these negative decisions because they show restraint.
Interview moment | What to say | Why it helps |
|---|---|---|
Opening | I will start with a modular monolith and 3-tier deployment. | Shows practical simplicity |
Scaling traffic | Scale API horizontally, cache reads, move slow work to queues. | Connects pattern to workload |
Scaling teams | Split payment, notification, or delivery only when ownership pressure is real. | Avoids premature microservices |
Data consistency | Use local transactions inside services and sagas/outbox/idempotency across services. | Addresses distributed data honestly |
Reliability | Use timeouts, retries, DLQs, correlation IDs, and graceful degradation. | Shows production thinking |
Advanced patterns | Use CQRS or event sourcing only for reporting, audit, or replay needs. | Shows restraint with complexity |
This walkthrough is deliberately ordinary. It does not try to impress with a final diagram full of fashionable names. It demonstrates that architecture is a conversation with constraints. As the interviewer changes the constraints, you reshape the architecture. That is the habit they are testing.
A useful interview rhythm is: state current assumptions, choose the simple baseline, name the first bottleneck, add the smallest pattern that solves it, then mention the tradeoff and rollback path. For example, if notifications slow checkout, move notifications to a queue, but also add retry limits, DLQ inspection, idempotency, and user-visible order status. That answer is much stronger than simply saying, we will use a message broker.
How to Score Your Own Architecture Answer
After you explain an architecture, pause and score it against five questions. First, did you explain why the pattern appears now? Second, did you keep the first version simple enough for the team? Third, did you protect the system from the most likely failure? Fourth, did you describe how data stays correct? Fifth, did you say what you would measure before moving to the next pattern?
For ChaiCart, a good answer does not need every possible component. It needs the right sequence. If you start with microservices, you must explain why a small chai shop already has multiple teams, independent release cycles, and operational maturity. If you start with a monolith, you must explain how you will keep it modular and how you will move slow work outside checkout when traffic grows.
The interviewer is often listening for restraint as much as ambition. A candidate who says, I would not split payment yet; I would first isolate it as a module and add idempotency around callbacks sounds more production-ready than a candidate who immediately creates ten services. Restraint is not lack of knowledge. It is knowledge under control.
Also score your data story. In a monolith, local transactions are simple, but shared tables can become messy. In microservices, ownership is clearer, but cross-service consistency must be designed. In event-driven workflows, the event log can power many consumers, but duplicate events, schema changes, and dead-letter handling become part of the design. Every data choice should have a correctness plan.
Finally, score your operations story. If you add queues, say how you monitor queue depth and failed messages. If you add microservices, say how you trace one order across services. If you add read models, say how you detect projection lag. If you add caching, say which data can be stale and how invalidation works. Architecture that cannot be operated is only a diagram.
Self-check | Strong answer signal | Weak answer signal |
|---|---|---|
Reason for pattern | Pattern follows named pressure | Pattern appears because it sounds advanced |
Team fit | Matches team size and release maturity | Assumes enterprise operations on day one |
Data correctness | Explains transactions, ownership, and consistency | Ignores duplicate writes and partial failures |
Failure handling | Mentions retries, timeouts, DLQ, graceful degradation | Assumes every dependency is healthy |
Evolution path | Shows what changes only when pressure increases | Draws final architecture immediately |
Observability | Uses logs, metrics, traces, IDs, dashboards | Debugging depends on manual guessing |
This self-check turns architecture from memorization into judgment. When you can explain why a simple design is enough today and what evidence would justify the next step tomorrow, you sound like someone who can build systems, not only recite patterns.
Checkpoint: your architecture answer should sound like a sequence of responsible tradeoffs.
30. Full Architecture FAQ
Software Architecture Patterns FAQ
What is software architecture?
Software architecture is the high-level structure of a system: components, responsibilities, communication, data ownership, deployment shape, and failure behavior. It explains how the system is organized so it can satisfy business requirements such as performance, reliability, security, scalability, and maintainability. In ChaiCart, architecture decides where order logic, payment logic, delivery rules, and reporting data live.
Why does software architecture matter in system design?
Architecture matters because system design is not only about choosing technologies. It is about choosing boundaries. Good architecture helps a system scale, change safely, recover from failure, and remain understandable as teams grow. In interviews, architecture shows whether you can connect requirements to practical tradeoffs instead of naming random components.
What is the difference between monolithic and microservices architecture?
A monolith is one deployable application that usually contains multiple modules and often shares one database. Microservices split the system into independently deployable services organized around business capabilities. Monoliths are simpler to build and operate early. Microservices improve independent ownership and scaling, but add distributed-system complexity such as network failures, tracing, versioning, and eventual consistency.
When should you choose layered architecture over microservices?
Choose layered architecture when the main problem is code organization, not independent deployment. If ChaiCart has one team, one release cycle, and mostly shared transactions, a layered modular monolith is usually better than microservices. It gives separation of concerns without adding network calls, distributed data ownership, service monitoring, and complicated deployment pipelines.
What are the pros and cons of event-driven architecture?
Event-driven architecture decouples producers from consumers, moves slow work out of request paths, handles bursts better, and allows multiple services to react to the same business event. The costs are eventual consistency, duplicate and out-of-order events, schema evolution, retry design, dead-letter handling, and harder debugging. It is powerful, but it needs operational discipline.
How does architecture impact scalability and performance?
Architecture decides what can scale independently. A monolith often scales as one unit. N-tier systems can scale web, API, cache, worker, and database tiers differently. Microservices can scale specific business services. Event-driven systems can absorb bursts with queues. Performance improves when architecture puts heavy reads, slow tasks, and bursty work in the right places.
How do business requirements influence architectural decisions?
Business requirements are the real starting point. A small MVP values speed and simplicity, so a monolith may be best. A city-wide ordering platform may need queues, caches, and workers. A company with separate payment, delivery, and menu teams may need service boundaries. Strict audit requirements may justify event sourcing. Architecture follows business pressure.
What are the key differences between layered and client-server architecture?
Client-server describes communication between a client that asks and a server that answers. Layered architecture describes how responsibilities are organized inside the server or application. A ChaiCart mobile app calling an API is client-server. The API separating routes, services, repositories, and integrations is layered architecture. They can exist together.
What are the challenges of maintaining a monolithic architecture as it grows?
A growing monolith can develop tangled dependencies, risky deployments, slow test suites, shared failure blast radius, and team conflicts. The answer is not always microservices. First, modularize the monolith, clarify layers, add tests, improve deployment, separate heavy background work, and protect database boundaries. Split services only when pressure remains specific and strong.
How do you decide between monolithic and microservices architecture for a new system?
For a new system, start by asking about team size, release frequency, expected scale, data consistency, operational maturity, and business boundaries. If one small team owns the whole product, a modular monolith is usually safer. If independent teams own stable business capabilities and have strong DevOps, observability, and on-call practices, microservices may be justified.
What role does fault tolerance play in microservices?
Fault tolerance is central to microservices because every network call can fail. Services need timeouts, retries with backoff, circuit breakers, idempotency, graceful degradation, and clear fallbacks. ChaiCart should not let a notification outage block checkout. Service boundaries are useful only when failure is isolated and visible.
How do event-driven systems handle real-time data?
Event-driven systems handle real-time data by publishing events as soon as business facts occur. Brokers or streams deliver those events to consumers that update dashboards, send notifications, or trigger workflows. Streaming platforms can store events durably and let consumers process them continuously. The design must handle ordering, lag, duplicates, and replay.
Multi-Tier Architecture FAQ
What is Multi-Tier Architecture and why is it used?
Multi-tier architecture separates a system into multiple deployment or responsibility tiers. It is used to improve maintainability, scalability, security, and isolation. In ChaiCart, presentation, API, cache, worker, database, and analytics tiers can be separated so each tier can be secured, monitored, scaled, and changed according to its workload.
How does 2-tier architecture differ from 3-tier architecture?
In 2-tier architecture, the client often talks directly to the data layer or a very thin server. In 3-tier architecture, the client talks to an application tier, and the application tier talks to the data tier. 3-tier improves security and business-rule control because public clients do not directly access the database.
What are the key components of 3-tier architecture?
The key components are presentation tier, application tier, and data tier. The presentation tier renders screens and collects input. The application tier handles APIs, authorization, validation, business logic, and orchestration. The data tier stores persistent data such as users, menu, orders, payments, and delivery records.
What is a real-world example of N-tier architecture?
A real-world N-tier ChaiCart system might include CDN, load balancer, web tier, API tier, cache tier, queue tier, worker tier, search tier, primary database, read replica, analytics store, and object storage. Each tier exists because a particular workload needs performance, isolation, scaling, or reliability.
How does scalability improve in multi-tier architecture?
Scalability improves because different tiers can scale separately. If menu reads are heavy, cache and CDN can scale. If checkout is busy, API instances can scale. If notifications spike, workers can scale. If reporting is expensive, read replicas or analytics stores can protect the primary transaction database.
What are the challenges of adding more tiers?
More tiers add latency, cost, monitoring needs, deployment complexity, configuration drift, and new failure paths. Each network hop can fail or slow down. Teams need observability, health checks, retries, ownership, and runbooks. Adding a tier is worthwhile only when it solves a real workload, security, or reliability problem.
How does load balancing work in N-tier architecture?
A load balancer distributes incoming traffic across healthy instances of a tier, such as web servers or API servers. It improves availability and capacity by avoiding a single overloaded instance. In ChaiCart, a load balancer can route checkout traffic across multiple API instances while removing unhealthy ones from rotation.
What strategies reduce latency in multi-tier systems?
Latency can be reduced with caching, CDN, connection pooling, database indexing, fewer chatty calls, asynchronous background work, regional placement, efficient serialization, and careful timeout budgets. The best strategy depends on where the time is spent. Measure before adding complexity, because extra tiers can also increase latency.
When should a large-scale system choose microservices over N-tier architecture?
Choose microservices over only N-tier boundaries when independent business ownership, independent deployment, and independent scaling are stronger needs than simple infrastructure separation. N-tier separates technical workloads. Microservices separate business capabilities. A large ChaiCart with separate payment, delivery, and menu teams may need both.
How do you secure communication between tiers?
Secure inter-tier communication with authentication, authorization, TLS, private networking, least-privilege credentials, service identities, input validation, rate limits, secrets management, audit logs, and network policies. Each tier should expose only the minimum surface required by the tier that calls it.
How do you design fault-tolerant multi-tier systems for high traffic like Netflix or Amazon?
Fault-tolerant high-traffic systems use redundancy across instances and regions, load balancing, graceful degradation, caching, queues, retries with backoff, circuit breakers, health checks, autoscaling, observability, and disaster recovery plans. The exact design depends on product needs, but the principle is the same: no single tier should silently take down the whole experience.
Microservices Architecture FAQ
What are microservices and how do they differ from monoliths?
Microservices are independently deployable services organized around business capabilities. A monolith packages many capabilities into one deployable application. Microservices improve independent ownership and scaling, but they add distributed-system complexity. A monolith is simpler early, while microservices fit better when multiple teams need autonomy and the business boundaries are clear.
What are the benefits and challenges of microservices?
Benefits include independent deployment, service-specific scaling, clearer ownership, technology flexibility, and better fault isolation when designed well. Challenges include distributed data consistency, network failures, observability, deployment complexity, API versioning, security, duplicate logic, and higher operational cost. Microservices require both architecture discipline and platform maturity.
How do you identify and design microservices?
Identify microservices around business capabilities and data ownership, not around random technical nouns. Look for features that change independently, scale differently, have clear domain rules, and can own their own data. For ChaiCart, Order, Payment, Delivery, Menu, Coupon, and Notification are plausible boundaries because they have distinct responsibilities.
What is an API Gateway and why is it used?
An API Gateway is a front door for client requests in a service-based system. It can handle routing, authentication, rate limiting, request shaping, aggregation, and observability. In ChaiCart, clients can call one gateway instead of knowing every internal service. The gateway should not become a giant business-logic monolith.
How do microservices communicate?
Microservices communicate through synchronous APIs such as REST or gRPC, asynchronous queues, event buses, and event streams. Use synchronous calls when the caller needs an immediate answer. Use asynchronous messaging when work can happen later, multiple consumers need the same fact, or bursts should be absorbed without blocking users.
How do microservices ensure data consistency?
Microservices often use eventual consistency patterns instead of one global transaction. Common approaches include sagas, outbox pattern, idempotent consumers, compensating actions, read projections, and clear user-visible status. The goal is not to pretend everything is instantly consistent, but to manage progress safely and transparently.
What are common microservice deployment strategies?
Common strategies include rolling deployments, blue-green deployments, canary releases, feature flags, and quick rollback. Services need versioned APIs and compatibility because other services may still call older behavior. Deployment independence works only when teams can observe, test, and rollback services safely.
What are common scaling strategies for microservices?
Scaling strategies include horizontal scaling of stateless services, autoscaling based on queue depth or traffic, caching, database read replicas, partitioning, asynchronous workers, and separating read-heavy workloads from write-heavy workloads. Scale the bottleneck, not the whole diagram. Payment and notification workloads may need very different scaling rules.
What are real-world examples of microservices?
Large commerce, streaming, ride-sharing, delivery, and banking systems often use service-based architectures for independent domains such as catalog, payment, recommendation, delivery, identity, and notification. The useful lesson is not to copy their exact architecture, but to understand why separate teams, traffic patterns, and reliability needs pushed them there.
What are monitoring and debugging best practices for microservices?
Use centralized logs, distributed tracing, metrics, correlation IDs, structured events, service dashboards, error budgets, health checks, and alerting tied to user impact. ChaiCart should be able to trace one order from checkout through payment, delivery, notification, and support projection without guessing across five systems.
Event-Driven Architecture FAQ
What is EDA and how does it differ from request-response?
Event-driven architecture lets services publish and react to events that represent facts. Request-response is direct: caller asks, callee answers. EDA is indirect: producer publishes OrderPlaced, and consumers react. Request-response is simpler for immediate decisions. EDA is better for decoupled follow-up work, fanout, bursts, and real-time pipelines.
What is Pub-Sub vs Event Streaming?
Pub-sub broadcasts messages to subscribers, often for active fanout. Event streaming stores events in a durable ordered log so consumers can read, replay, and process history. RabbitMQ is often used for messaging and pub-sub patterns. Kafka is designed as an event streaming platform with durable topics and consumer offsets.
What are the components of an event-driven system?
The core components are event producers, event brokers or streams, event consumers, event schemas, retry policies, dead-letter queues, monitoring, and storage for processed-event tracking. ChaiCart's Order service can produce OrderPlaced, while Payment, Notification, Analytics, and Loyalty consume it for different purposes.
What are the challenges of EDA and eventual consistency?
EDA challenges include delayed state, duplicate events, out-of-order events, schema changes, poison messages, difficult tracing, and user confusion if status is unclear. Eventual consistency means systems may briefly disagree. Good design makes that state visible, recoverable, and safe through retries, idempotency, projections, and support tooling.
How do event-driven systems ensure event ordering?
Ordering is usually handled by partitioning or grouping events by an aggregate key such as orderId. Events for the same order can go to the same partition, preserving local order. Global ordering across all events is expensive and rarely necessary. Design around the ordering level the business actually needs.
What are dead-letter queues and why are they important?
Dead-letter queues store messages that could not be processed successfully after retry limits. They are important because one bad message should not block the whole queue forever. Engineers can inspect DLQ messages, fix payload or consumer issues, redrive safe messages, and monitor failure patterns.
Kafka vs RabbitMQ vs AWS EventBridge: when should you use each?
Use Kafka when you need durable event streams, replay, high throughput, and stream processing. Use RabbitMQ when you need mature messaging, work queues, routing, and pub-sub style fanout. Use AWS EventBridge when you want a managed event bus with AWS and SaaS integrations. Tool choice follows workload shape.
What is idempotent processing?
Idempotent processing means handling the same event more than once produces the same final result as handling it once. This is essential because distributed systems can deliver duplicate messages. ChaiCart can store processed event IDs or use idempotency keys so duplicate PaymentCaptured does not double-confirm or double-refund an order.
What is a real-world example where EDA is better?
Order confirmation is a good example. After ChaiCart creates an order, payment, delivery, notification, analytics, and loyalty workflows may all need to react. Calling every system synchronously would slow checkout and couple services tightly. Publishing OrderPlaced lets each consumer work independently with retries and observability.
What are schema evolution strategies in EDA?
Schema evolution strategies include backward-compatible changes, optional fields, versioned event names, schema registry checks, consumer-driven contracts, and deprecation windows. Do not remove or rename fields without knowing which consumers rely on them. Events are public contracts inside your system, so changing them requires care.
31. Cheat Sheet and Final Mental Model
If you remember one thing from this article, remember ChaiCart's staircase. A small product starts simple. Then it organizes responsibilities. Then it separates public clients from business rules and data. Then it adds infrastructure tiers where workloads demand them. Then it splits services where ownership and scaling prove the need. Then it uses events where direct calls would make the system slow or tightly coupled.
The best architecture is not the biggest diagram; it is the clearest set of boundaries for the pressure your system actually has.
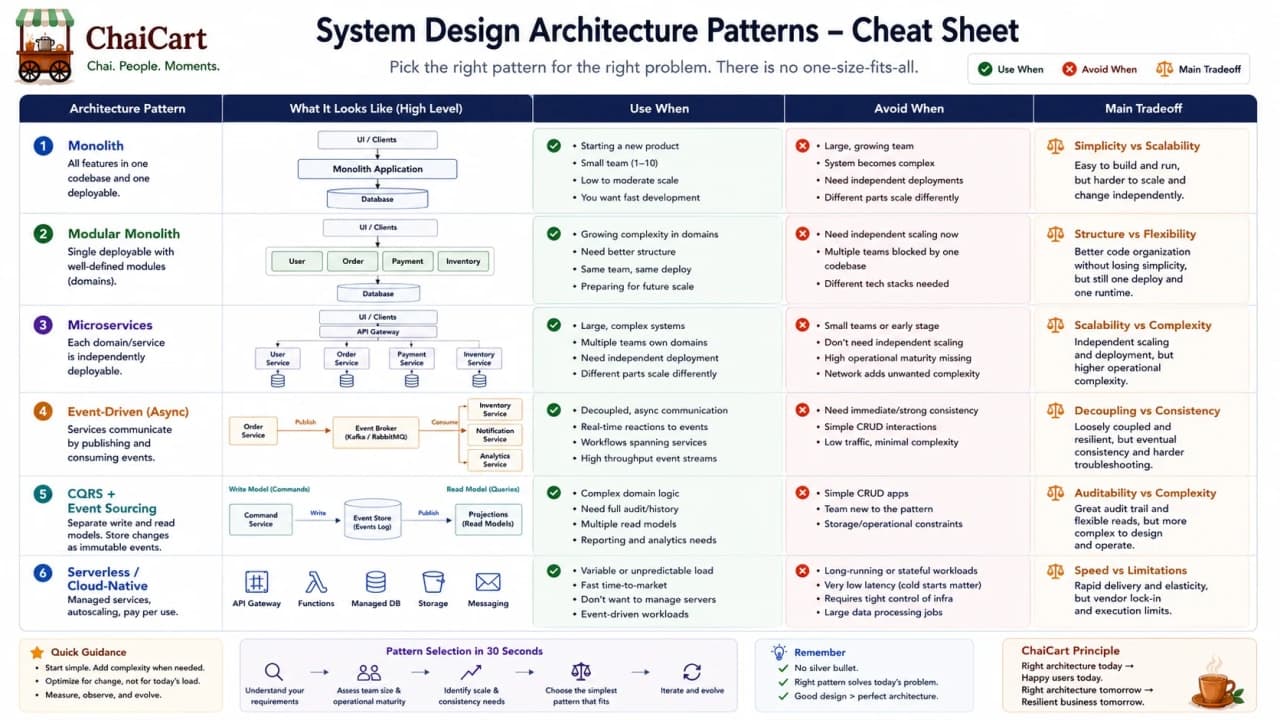
Pattern | Use when | Avoid when | Core tradeoff |
|---|---|---|---|
Monolith | Small team, early product, shared transactions | Independent teams and scaling needs are strong | Simple operation vs shared blast radius |
Layered architecture | Code needs responsibility boundaries | Layers become pass-through ceremony | Clarity vs extra structure |
2-tier | Small trusted internal tools | Public clients or high scale | Simplicity vs security and scaling risk |
3-tier | Normal public web/mobile app | Ultra-simple trusted local tool | Security and control vs extra tier |
N-tier | Workloads need specialized scaling or isolation | Tiers have no clear purpose | Isolation vs latency and operations |
Microservices | Independent business ownership and deployment matter | Team and operations are not ready | Autonomy vs distributed complexity |
Event-driven | Many consumers react to facts or slow work can happen later | Immediate consistency is required everywhere | Decoupling vs eventual consistency |
CQRS/event sourcing | Reads/writes differ strongly or audit history matters | CRUD app is simple | Powerful models vs advanced complexity |
So when you answer architecture questions, do not rush to the most glamorous pattern. Tell the story. Start with the business. Name the pressure. Pick the pattern. Explain the tradeoff. Then show how the next stage would evolve only when the current stage starts to bend.
Final mental model: monolith for speed, layers for clarity, tiers for workload separation, microservices for ownership, events for decoupled reactions, CQRS/event sourcing for specialized read/write and history needs.
Research Notes and Further Reading
This draft used the attached interview PDFs as the article spine and cross-checked key concepts against current official or primary references, including Martin Fowler on microservices, AWS event-driven architecture guidance, Microsoft's CQRS pattern, Microsoft's event sourcing pattern, Apache Kafka's introduction, RabbitMQ publish-subscribe docs, and AWS SQS dead-letter queue docs.
Frequently asked questions
What is software architecture?
Software architecture is the high-level structure of a system: components, responsibilities, communication, data ownership, deployment shape, and failure behavior.
Why does software architecture matter in system design?
It connects requirements to boundaries, tradeoffs, scalability, reliability, maintainability, and how the system changes over time.
What is the difference between monolithic and microservices architecture?
A monolith is one deployable application. Microservices are independently deployable services organized around business capabilities.
When should you choose layered architecture over microservices?
Choose layered architecture when the main problem is code organization and one team still owns one releaseable application.
What are the pros and cons of event-driven architecture?
EDA decouples services and handles bursts, but introduces eventual consistency, duplicate events, ordering concerns, schema evolution, and retry design.
How does architecture impact scalability and performance?
Architecture decides which parts can scale independently, which work can be cached, and which slow tasks can move out of the request path.
What is multi-tier architecture?
Multi-tier architecture separates a system into multiple tiers such as presentation, API, cache, workers, database, and analytics.
How does 2-tier differ from 3-tier?
In 2-tier, clients may talk directly to data or a thin server. In 3-tier, clients talk to an application tier, which protects the data tier.
What are microservices?
Microservices are independently deployable services with clear business ownership, APIs or events, and usually independent data ownership.
How do microservices ensure data consistency?
They use patterns such as sagas, outbox, idempotent consumers, compensating actions, and read projections instead of one global transaction.
What is Pub-Sub vs Event Streaming?
Pub-sub broadcasts messages to subscribers. Event streaming stores durable event logs that consumers can process and replay.
What are dead-letter queues and why are they important?
Dead-letter queues store messages that repeatedly fail processing so engineers can investigate without blocking the whole queue.
